The Shibboleth IdP V3 software has reached its End of Life and is no longer supported. This documentation is available for historical purposes only. See the IDP4 wiki space for current documentation on the supported version.
BuildingExtensions
There are some basic design and coding concepts to be aware of in developing extensions.
Project Structure and API Boundary
The software is made up of several independent projects that are in theory managed and versioned independently; in practice, they all tend to be released in tandem with new IdP releases. The projects and their internal organization are:
- java-parent-project-v3 (a Maven parent POM)
- java-support (single module, contains low level supporting classes)
- spring-extensions (single module, contains Spring support classes)
- java-opensaml (multi-module, contains a lot of core code for XML processing, security processing, messaging and profile abstractions, SAML function, storage, and generally anything without Spring dependencies)
- java-identity-provider (multi-module, everything else, configuration handling, packaging, installer code, and all attribute-related functionality)
You should read, and thoroughly understand, the Java Product Version Policy, as it governs the rules you must follow if you want to guarantee a stable extension life cycle, and in particular if you intend to target multiple versions of the IdP with your extension.
As the policy states, currently all of the code in the java-support and spring-extensions modules are part of the public API (by virtue of the fact that none of the packages at the time of authoring this page contain "impl" as a segment).
As the policy states, all of the OpenSAML and IdP modules that end in -api are part of the public API and all of the rest of the modules are not part of the API with the following exceptions that are mostly part of the public API despite the names:
- opensaml-core
- idp-core
- idp-schema (this contains no code, but the XML schemas are part of the public API)
- idp-ui
The exception to the above list is any class within a package containing "impl" as a segment.
If you have any doubts regarding the above, we suggest asking rather than operating in doubt. You will find that there is a significant amount of useful code in the implementation modules, and you may well want to use it. We suggest you copy that code rather than violating the API boundary. You may also inquire about the possibility of the code being promoted into the API in a future version. We intentionally erred on the conservative side to avoid over-comitting to APIs so early in the lifecycle.
Logging
Developers should only use the SLF4J API for logging. If you absolutely must use a different API, you will create problems for deployers unless you use an API that the SLF4J project provides a shim for and confine your use of the alternative API to calls supported by that shim.
Annotations
There is widespread use of code-contract annotations across the API, particularly @Nullable / @Nonnull indicators on parameters or return values. We strive to make these accurate and we consider these annotations a formal part of the API; that is, changing a method from one that allows null parameters to one that does not would be a change, but a compatible one. Similarly, changing a method from one that may not return a null to one that may would be considered an incompatible change.
Some methods do check their parameters, but any parameter annotated as non-null signifies that its method is free to throw a runtime exception on null input.
In contrast to the above, we do not make essentially any use of true runtime annotations to handle configuration of components by Spring, and strongly discourage this technique. There are a small number of exceptions, such as the @Duration annotation supporting Spring conversion of XML duration syntax into milliseconds, but we are phasing that out in V4.
Components, Initialization, and Destruction
You will frequently encounter component interfaces that provide some basic lifecycle management for beans, principally:
- net.shibboleth.utilities.java.support.component.InitializableComponent
- net.shibboleth.utilities.java.support.component.DestructableComponent
Typically these interfaces are wired to Spring's lifecycle support, particularly so that beans created by Spring will be initialized explicitly separately from the object's constructor, allowing properties to be set first. You should generally take advantage of that support and implement that interface when creating stand alone beans.
Component destruction is supported, but is often not possible because the dominant pattern within the IdP's Spring Web Flow action architecture is the use of prototype beans, for which Spring will not call lifecycle-closing methods. Components that need a destruction feature should be implemented as singletons and should generally be injected into Spring Web Flow actions that are themselves prototypes.
Components that support lifecycle interfaces can if they choose support redundant/recursive lifecycle calls or may throw exceptions (refusing to initialize an already-initialized component for example). They may also support initialization after destruction or may refuse to do so, again by throwing exceptions as appropriate. In practice, the common pattern within the IdP is to avoid any attempts to reuse destroyed components. When services are reloaded, new components are created to replace the older ones.
Lifecycle Propagation
Many components within the IdP accept other components as plugins. For example, the attribute resolver, which is a component, accepts any number of attribute definitions and data connectors, which are also components. In most cases, enclosing components should not propagate lifecycle calls to injected components because Spring will perform that function on behalf of the system.
In special cases where DI via Spring is not being used, components may understand that they bear the responsibility to manage the lifecycle of embedded components that they create for themselves.
Services
The distinguishing characteristic of a "service" vs. a component, aside from interface considerations, is that a service is an encapsulation of function that generally manages its own configuration, typically in a fashion that allows for optional reloadability of the configuration at runtime.
In most cases, extensions from a third party will not need to support this kind of encapsulation, typically being implementations of either more fine-grained APIs, or actual high-level feature additions that are implemented as webflows. However, we fully support the total replacement of any of the services supplied with the IdP should someone wish to do so.
Managing this capability requires the use of a pair of low-level interfaces:
- net.shibboleth.utilities.java.support.service.ReloadableService<T>
- net.shibboleth.utilities.java.support.service.ServiceableComponent<T>
Services that implement these related interfaces require a specific interaction pattern. The ReloadableService is the injectable type from a DI perspective. Accessing the underlying service API (which is represented by T above) involves the getServiceableComponent() method, which returns the ServiceableComponent wrapper for the service API, in a so-called "pinned" state, meaning it is locked and accessible. When finished, the unpinComponent() method is called (usually in a finally clause) to release the lock.
The locking regulates the service's ability to reload itself either internally or externally and ensures thread safety.
Any actual API can be wrapped in the service abstraction, and when APIs are stateless, the service interfaces can often be wrapped in a facade that implements the original API while internally delegating to a wrapped instance of the API, hiding the details of this interaction pattern.
The IdP makes use of these patterns extensively, and the spring-extensions module contains additional code that binds the service abstraction to Spring configuration so that a service can be managed with Spring but remain safely reloadable (something Spring handles very poorly on its own).
Contexts
A core concept in the "meat" of the IdP, and in OpenSAML's messaging code, is the notion of a context. All contexts implement the BaseContext interface and are simply Java beans that store state relevant to an operation.
Within the IdP, contexts are arranged in a tree structure with the root generally represented by the ProfileRequestContext class. Hanging off of this root node are contexts related to other units of state (e.g., session information, attribute information, relying party information). Child nodes may themselves have children but we try and keep the tree relatively shallow and wide. So, you end up with something like this:
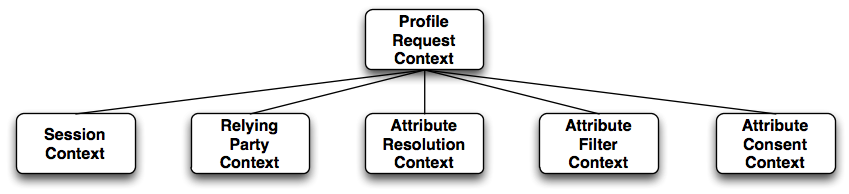
To navigate the context tree, the getParent() and getSubcontext() methods are used. So for example, if an attribute resolver class needs to access the current session information, it might do something like:
SessionContext sessionContext;
BaseContext parent = resolutionContext.getParent();
if(parent != null) {
sessionContext = parent.getSubcontext(SessionContext.class);
}
This approach has a number of benefits:
- it provides strongly-typed access to data (as opposed to just using a map, which is really all these context implementations are)
- new contexts can be added to the tree in the future (by new code or extensions) without disrupting existing code
- existing contexts can be extended without disrupting existing code
- different subsystems can operate on parts of the tree without concerning themselves with the rest of it
However this approach does have some drawbacks as well:
- developers need to document what they require from the tree and what they add to the tree (and thus what other code can depend on)
- documenting the tree isn't something that lends itself to typical API documentation approaches and we haven't really come up with anything for that as of yet, apart from simple diagrams and prose
- it's a bit of a learning curve for developers
Persistence
Most requirements for persistence should, if possible, be met using the org.opensaml.storage.StorageService interface. This is a thread-safe API for storing, updating, reading, and deleting records that uses a very particular and precise API contract that individual use cases generally need to adapt themselves to, sometimes with a fair degree of creativity. In return, you can essentially ignore the details of how the data will be stored. Interfaces are also provided to interrogate the service's capabilities if you need to make sure that you can store keys and data of a certain size.
You will often find that using this API will be less than optimal in terms of performance or code design, but the advantages for deployers are substantial, and we urge people to exhaust every last possible trick to avoid creating a dedicated persistence solution specific to an extension. We already have one such case (storing SAML persistent IDs) and we want to avoid seeing more. The chances of any extension being accepted into the code base are close to zero if it implements its own persistence.
Spring Configuration 3.2
Out of the box, the IdP allows injection of beans from files resident on the classpath. This allows you to initialize your system. Three locations are supported
/META-INF/net.shibboleth.idp/preconfig.xml3.3 will be loaded before the IdP configuration/META-INF/net.shibboleth.idp/config.xml3.2 will be loaded after the IdP configuration. This location, introduced in V3.2, is deprecated in V3.3/META-INF/net.shibboleth.idp/postconfig.xml3.3 will be loaded after the IdP configuration.
Spring WebFlow Configuration 3.3
Refer to the SpringConfiguration documentation section on webflows for a summary of how you can register flows from extension libraries at runtime.
Typically, the convention is to put the Spring beans that define the flow's objects into the same directory with the flow file and then import it into the flow file.
Naming Recommendations
If extensions define names for properties, beans, storage contexts or cookies, it's best to adhere to the recommendations listed below to avoid conflicts with existing names. Property names should not start with "idp.", bean names should not start with "shibboleth.", as these prefixes are reserved by the core project. It's recommended to choose your organization's Internet domain name in reverse order (or some other domain related to your extension) as the base for naming, e.g. "org.example". The following recommendations refer to this name as "base name". If you're implementing Java classes, you may just use your classes' package names (or parts of it) for building the various names.
Properties (configuration properties and message translation keys):
- Prefix all properties with the base name.
Examples: "org.example.idp.foo.storage.StorageService", "org.example.idp.foo.authn.apiHost"
Beans:
- Prefix the names of all beans defined in a global context with the base name.
Example: "org.example.idp.foo.authn.ClassifiedMessageMap"
Storage Contexts:
- For persisting data via the org.opensaml.storage.StorageService interface, you need to specify a context name. Prefix the context names with the base name.
Example: "org.example.idp.foo.authn/rememberSelection"
Cookies:
- Prefix the names of cookies with the base name, replacing dots with dashes. (Dots are allowed, but seem not to be widely used.)
Example: "org_example_idp_foo_rememberSelection"